It really isn't that difficult, but I documented the process here for myself and hopefully others:
Before starting, all of your addresses should be in a spreadsheet, with each column representing a unique bit of information. What I'm doing is:
- Addresses are stored in a Google Docs spreadsheet which both my wife and I have access to
- I want to use LibreOffice to print labels using this spreadsheet as a source
To start, I export the Google Docs spreadsheet to LibreOffice format. Now:
1. Start LibreOffice Base (if you don't have Base, you may need to install it: sudo apt-get install libreoffice-base)
2. Create a new database from spreadsheet.
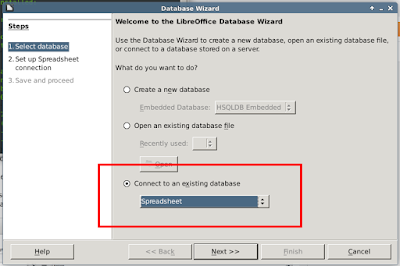
3. Point to the spreadsheet that contains your addresses.
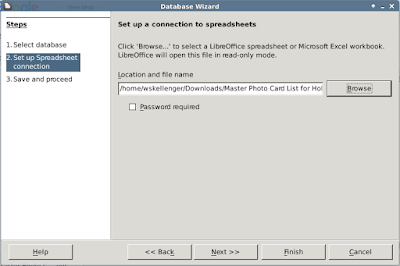
4. Allow Base to register the database for you, because you will need to see it from the word processor.
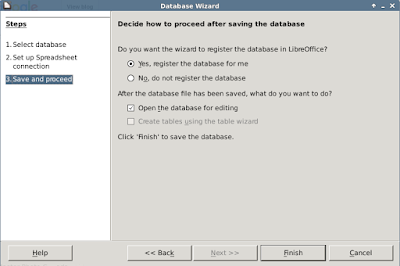
5. Click 'Finish' and save the database.
6. Open LibreOffice Writer
2. Create a new database from spreadsheet.
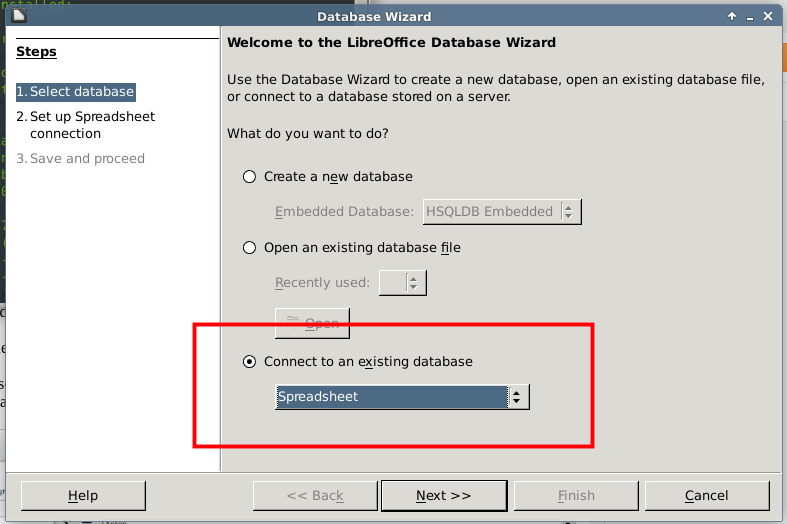
3. Point to the spreadsheet that contains your addresses.

4. Allow Base to register the database for you, because you will need to see it from the word processor.

5. Click 'Finish' and save the database.
6. Open LibreOffice Writer
7. Select File --> New --> Labels

8. In the resulting dialog, see below for detailed explanation:

A. Select the brand and type of labels you want to print.
B. Select the database you created earlier.
C. Select the table the data will come from (if you started with a spreadsheet there should probably only be one table here)
D. Select the field to add to the label
E. Add the field into the label
F. Repeat D and E, and arrange the fields in the "Label Text" box.
G. Finally make sure the correct printer is selected under the "Options" tab.
Note for section F I have arranged fields like so:
[First Name] [Last Name]
[Address]
[City], [State] [Zip]
9. Go to the options tab. This is critical.
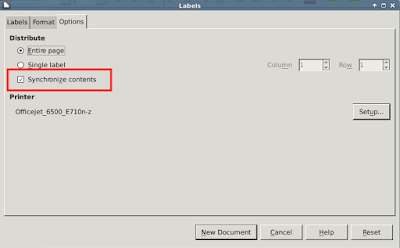
Select "Synchronize contents" and set up your printer. The "Synchronize contents" option will allow you to manipulate the formatting of the first label, and apply those changes to all of the labels.
Click 'New Document' when you're finished.
10. Done.
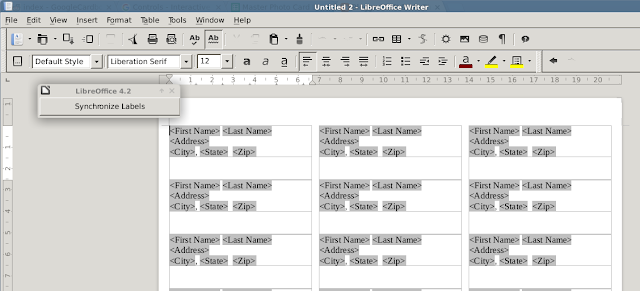
11. Now, we probably want to clean things up a bit. I like to center the address horizontally and vertically, and maybe change the font. Do this for the first label:
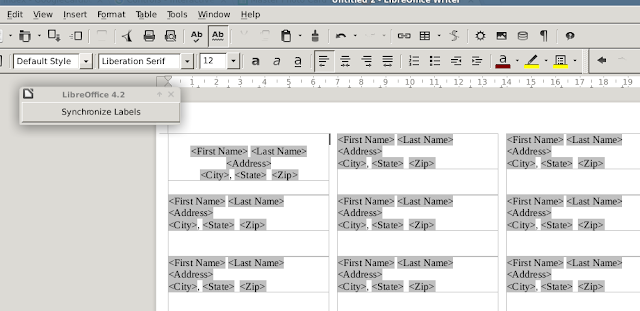
12. Once you've made your changes to the first label, click "Synchronize Labels" to apply the changes to all labels.
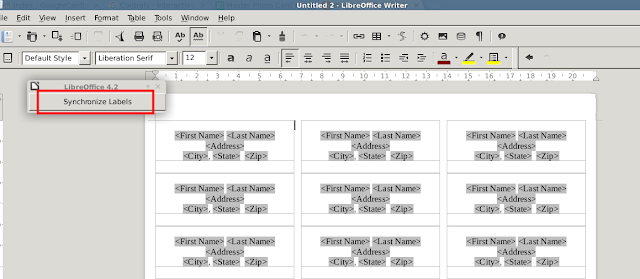
13. When you're done formatting, do File --> Print. You will get this message, to which you will click "Yes" to continue.
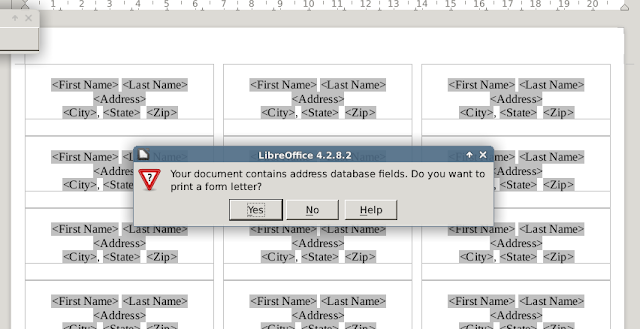
14. After clicking "Yes" you are presented with yet another dialog:
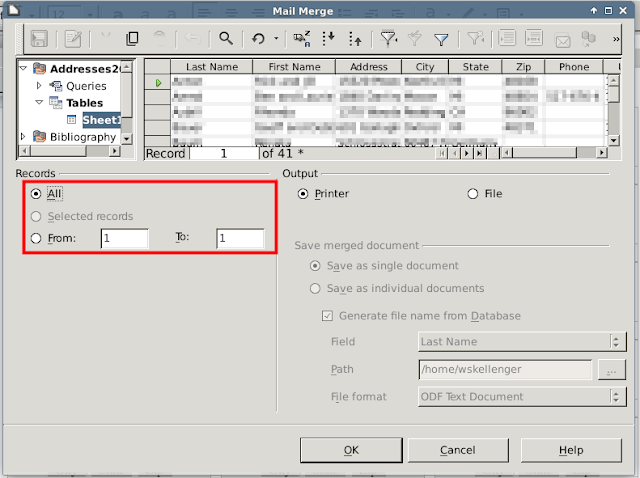
For the final project, you probably want to select "All" to merge all, but for a test, maybe try merging the first 10 records or so and printing.
When you have maybe addresses printed on plain paper, you can hold the plain paper over the labels, then hold them both up to bright light to see if the labels would align properly.
When you are satisfied, load labels and print.
B. Select the database you created earlier.
C. Select the table the data will come from (if you started with a spreadsheet there should probably only be one table here)
D. Select the field to add to the label
E. Add the field into the label
F. Repeat D and E, and arrange the fields in the "Label Text" box.
G. Finally make sure the correct printer is selected under the "Options" tab.
Note for section F I have arranged fields like so:
[First Name] [Last Name]
[Address]
[City], [State] [Zip]
9. Go to the options tab. This is critical.

Select "Synchronize contents" and set up your printer. The "Synchronize contents" option will allow you to manipulate the formatting of the first label, and apply those changes to all of the labels.
Click 'New Document' when you're finished.
10. Done.

11. Now, we probably want to clean things up a bit. I like to center the address horizontally and vertically, and maybe change the font. Do this for the first label:

12. Once you've made your changes to the first label, click "Synchronize Labels" to apply the changes to all labels.

13. When you're done formatting, do File --> Print. You will get this message, to which you will click "Yes" to continue.

14. After clicking "Yes" you are presented with yet another dialog:

For the final project, you probably want to select "All" to merge all, but for a test, maybe try merging the first 10 records or so and printing.
When you have maybe addresses printed on plain paper, you can hold the plain paper over the labels, then hold them both up to bright light to see if the labels would align properly.
When you are satisfied, load labels and print.





_021.png)
_022.png)















